1. 背景
最近一段时间在做安全大数据分析环境搭建以及初步的数据采集、录入工作,这个过程中用到了 Hadoop+HBase+Flume+Kafka这套大数据分析的工具。在数据分析环境架构中,Flume-1.7.0 主要用来收集各种来源、形式的数据,并把数据传给 Kafka 集群,由 Kafka 集群统一分发给 HBase 集群。
用 Flume ,主要用到的 Source 是 spooldir source 和 http-json source,Sink 就主要是 Kafka Sink,配置非常灵活、功能也很强大。但在使用的过程中踩了不少坑,撰文记录一下比较重要的几个。
NOTE:
Flume-ng的Agent由三部分组成:Source/Channel/Sink,Source相当于数据录入源,是 生产者 的角色;Channel相当于数据传输通道;Sink相当于数据接收端,是消费者的角色。在Flume-ng中,数据流向是Source-->Channel-->Sink。
2. kafka Sink 配置坑
2.1 LEADER_NOT_AVAILABLE Error
Kafka Sink ,顾名思义,即把 Kafka (集群或单个服务器)当做 Flume 的数据接收端(消费者),其中有一个配置项是配置 Kafka 的服务器:
这项配置中,如果只指定单个的 Kafka 服务器地址,Flume Agent 会正常运行,但如果把 Kafka 集群里的多个服务器地址都写上,并且Kafka的默认配置不修改,则会报以下错误:
并且数据无法正常发送到 Kafka 集群。该错误的意思是集群中的服务器,没有一个可用的 LEADER,导致数据无法正常 Fetch。那么解决方法也很简单,在 Kafka 集群的每个服务器 server.properties 配置文件中,开启(取消注释)以下配置,并把配置项的值改成统一指定的一台 Kafka 服务器做 LEADER:
2.2 useFlumeEventFormat 导致的 Flume Event Headers 乱码
Kafka Sink 中有这么一个配置项 useFlumeEventFormat,此配置默认关闭,官方解释如下;
By default events are put as bytes onto the Kafka topic directly from the event body. Set to true to store events as the Flume Avro binary format. Used in conjunction with the same property on the KafkaSource or with the parseAsFlumeEvent property on the Kafka Channel this will preserve any Flume headers for the producing side.
如果设置此项为 true,Kafka Sink 则会把数据按照标准的 Flume Event 格式(即Headers域和body域结合的数据结构)发送。Flume Event 中的 Headers 域通常是一些附加字段,可以是时间戳(比如时间戳拦截器指定的时间戳)、文件名(比如 spooldir Source 开启的 fileHeader = true)等信息。但是 1.7.0 版本的 Flume 一旦开启此配置,会导致 Headers 域里面的信息乱码,如下图所示: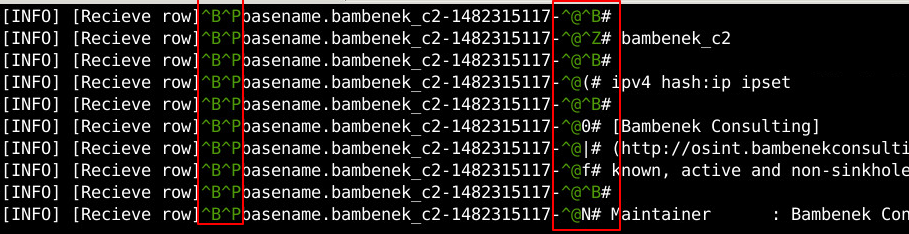
这可能是这个版本 Flume 的一个 Bug,原因未明,查各种资料也没查到,就剩翻源码了……
3. spooldir Source 的配置技巧
spooldir Source 的作用,是监控一个特定目录下的文件,一旦有新文件放入这个特定的目录,Flume 的 Agent 就会把整个文件的内容 逐行 读取,通过指定的 Channel 发送到指定的 Sink,并把已处理过的文件默认以.COMPLETED 后缀标记为已处理,或者直接删除。
早期版本的 Flume 中, spooldir Source 监控指定目录时,是不能监控子目录的,但我们用的 1.7.0 版本,提供了一个配置项可以监控指定目录下的子目录:
spooldir Source 的默认配置,用来监控一个目录下的同类型文件足够了,但是我们的需求有点复杂:首先,我们这个监控目录下的文件不是同一类型(尽管文件的内容结构类似,比如都是 IP 库,每行一个 IP);其次,我们的文件是一次性下载的,不是逐行写入的;最后,我们需要在逐行传输每个文件的时候,携带上文件所述的类型、文件生成的时间标记。
这个需求有两种处理方法:
- 每次下载一个文件,就用脚本自动化处理一下,把文件类型和时间戳加入文件的每一行中;
- 寄希望与 Flume,看 Flume 传输数据的时候能不能对数据进行一些自定义的修改——不修改本地文件,只在 Flume 传输文件的过程中修改一下。
无疑第一个工作量不小,而且比较耗费计算资源。去翻了下 Flume 的 用户手册 spooldir Source 部分,发现有一个配置项可以方便我们选第2中方法达成目标:
开启 fileHeader 会在 Flume 传输数据的时候,把数据所属文件的绝对路径附在每一行数据之前;开启 basenameHeader 会在 Flume 传输数据的时候,把数据所属文件的文件名附在每一行数据之前。
这样,我们把数据文件的文件名修改为 type-timestamp-的形式即可。比如我们生成一个名为 bambenek_c2-1478553609- 的文件,该文件里有数万行IP数据,那么 Flume 传输该数据的形式如下图所示: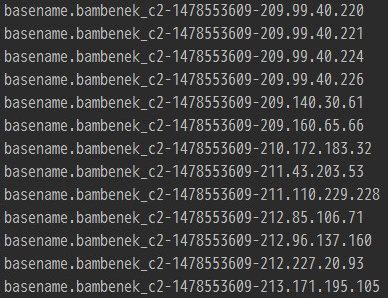
这样就满足了我们的需求,后台接收到数据之后,只需用 - 字符把每行数据 Split 成 3 个部分(文件名、时间戳、数据内容)即可。
NOTE:
其实,Flume 中还有功能更强大的Interceptors(拦截器),可以对其处理的数据进行更细粒度、方式更灵活的修改。参考 Flume Interceptors
4.http Source 的坑
这是最大的一个坑,不过踩的有点冤,如果把官方用户手册看仔细,并对 JSON 的数据格式有准确的理解,应该就不会掉坑了。
Flume 的 http Source,默认数据源的形式是接收第三方用 HTTP POST 方法发送过来的 JSON 格式的数据(默认的 Source 处理类 JSONHandler ,也可以自定义实现其他的数据处理类)。比如我们的应用场景,从网上抓取的威胁情报信息,Python 写的爬虫程序处理好之后,不用存库,直接整理成 JSON 格式,然后 POST 给 Flume 的 Agent 即可。
但是,Flume 的 http Source 对这种方式的 JSON 数据格式有严格的要求,如果 JSON 数据格式不符合要求,POST 过去数据就会发现服务端报错,如下图红框里的 JSON 数据,完全符合 JSON 数据格式规范,但 POST 请求发送之后就会收到 Request has invalid JSON Syntax. 的错误提示:
原因是什么?扒一下 Flume 的官方用户手册(http source–> JSONHandler)看一下:
A handler is provided out of the box which can handle events represented in JSON format, and supports UTF-8, UTF-16 and UTF-32 character sets. The handler accepts an array of events (even if there is only one event, the event has to be sent in an array) and converts them to a Flume event based on the encoding specified in the request. If no encoding is specified, UTF-8 is assumed
注意加粗部分,意思是该类(JSONHandler)处理的是 JSON 格式的 Flume Events(可以一次传输多个 Flume Events,即多组数据记录),接收的 JSON 数据必须是 array of events,即使只发送一个 Flume Event,也得按照 JSON Array 的格式发送。
什么意思?这里还要插播一下 JSON 数据格式规范。JSON 的数据格式里,基本元素是 值 或者 键值对,JSON 数据的值可以是以下几种:
- 数字(
bunber,整数或浮点数) - 字符串(
string,在双引号中) - 逻辑值(
bool,true 或 false) - 对象(
object,在花括号中,比如{"k1":"v1","k2":"v2"}) - 数组(
array,在方括号中,比如[{"k1":"v1",},{"k2":int_v2,"k3":"v3"}]) - null
并且官方给出了 JSON 示例:
但 Flume 官方手册没说明的是,Flume 的 Event 只有两部分组成:headers 和 body,所以传输的 JSON Array 里的 Flume Event,每个 Event 也只可以包括 headers 和 body 两部分,而且 headers的值是 JSON 对象(object),而body的值只能是 JSON 字符串(string),不能是其他 JSON 值类型,比如下图所示的 JSON 形式,对 Flume 来说算是合法的
另外,为了方便 Python 编程,附上 Python 中的 json 库里,Python 数据类型跟 JSON 值类型的对应关系表(参考: Python json.JSONEncoder()):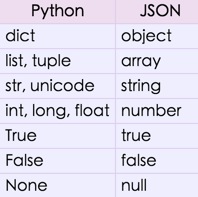
最后总结一下,传给 flume HTTP Source 的 JSON 数据:
- 必须是 Array 形式(用方括号括起来),即使 Array 里只有 1 个元素(每个元素到了 Flume 那儿就代表一个 Event),在 Python 里就要用
dict外面嵌套list或者tuple生成 JSON Array; - JSON Array 里每个元素必须由
headers和body两个 field 构成; - JSON Array 中元素的
headers的值是JSON Object(具体可以自定义),body的值必须是字串(JSON String),而不能是其他形式(JSONObject/JSON Array等,对应 Python 中的dict/list/tuple等)。